提高机器学习模型的容错性
不同的机器学习模型在错误标记的训练数据集上表现如何
两名可靠软件系统项目的学生完成了一个顶点项目,测试不同的机器学习模型如何处理错误标记的数据集。他们的结果令人惊讶——表明研究人员目前关于训练机器学习的最佳模型的假设是不正确的。

机器学习利用来自多个来源的广泛数据。如果数据是一致的、完整的、准确的、有效的和完整的,这是一个很好的方法。但这种情况有多常见呢?当包含错误、模糊、重复和不完整数据的数据集用于训练预测模型时,后果可能很严重。
两个学生在欢迎使用江南app 使用他们的顶点项目来评估不同的机器学习模型在错误标记的训练数据集上的表现。
评估集成学习
Debashis Kayal和西宁李的容错性特别感兴趣吗机器学习在错误标记的训练数据集上训练时的算法。他们的目标是集成学习,这是一种机器学习技术,它结合了几个模型来创建一个更好的预测模型,该模型更准确、更一致,并减少了偏差和方差误差。
“我们有两个主要问题,”德巴什说。“首先,集成学习能解决训练数据问题吗?如果是的话,增加多少?我们从一个非常开放的问题开始,然后将其缩小到专注于特定的机器学习模型和数据集。”
他们选择使用两个视觉识别数据集(MNIST和CIFAR-10),这两个数据集广泛用于基准模型的研究。然后,他们随机给30%的数据贴错标签,生成一个“坏数据集”,用来测试不同机器学习模型对数据错误的恢复能力。
在他们的第一个实验中,他们在干净的MNIST数据集和随机错误标记的MNIST数据集上训练了五个机器学习模型——逻辑回归、决策树、随机森林、AdaBoost和极端梯度增强。他们测量了每个人的F1分数,作为精确度和召回率的指标。
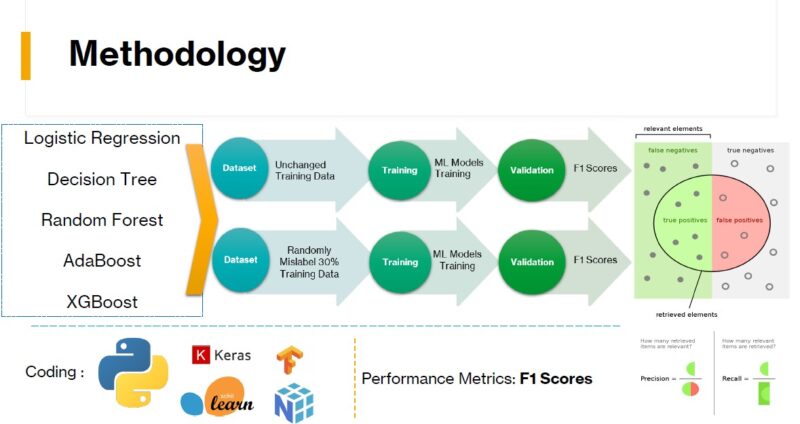
在机器学习模型中,那些整合了集成技术的模型表现出较少的退化,其中,随机森林对低质量数据表现出最大的弹性。
“我们对结果感到非常惊讶,”德巴什说。“我们所做的研究表明,极端梯度增强将是最好的集成学习技术。但最终,我们的结果表明,随机森林是处理错误标记或错误数据的最佳集成学习模型。”
改进卷积神经网络的性能
然后,他们进行了第二个实验,看看第一个实验中表现最好的机器学习模型是否可以提高卷积神经网络方法的性能。他们使用更复杂的CIFAR-10数据集进行了这个实验。结果表明,情况确实如此。
两人表示,他们的研究对理解不同的方法做出了宝贵的贡献。
“目前训练机器学习软件非常昂贵和耗时,”西宁说。“如果随机森林模型可以用于预训练,那将提高性能并降低训练成本。”
Debashis说:“我们的结论表明,在一个顶点项目中,两名学生进行的一个小实验可以挑战目前研究人员关于训练机器学习的最佳模型的主流假设。”“在这个领域还有很多研究要做,但这绝对让人大开眼界。”
申请的最后期限
2023年申请截止日期
2024年招生在线申请门户将于2023年1月1日开放。
第一轮:2023年3月30日
第二轮:2023年6月30日
第三轮(仅限加拿大公民、加拿大永久居民和美国公民):2023年8月30日
有关详细信息,请参阅如何申请一节。
如何申请
